(Chen et al., 2022)
(Hu et al., 2021)
(Hu et al., 2020)
(Chen et al., 2019)
(Rosa et al., 2018)
(Wang et al., 2018)
(Wang et al., 2018)
(Xie et al., 2018)
(Wang et al., 2018)
(Rosa et al., 2018)
References
2022
-
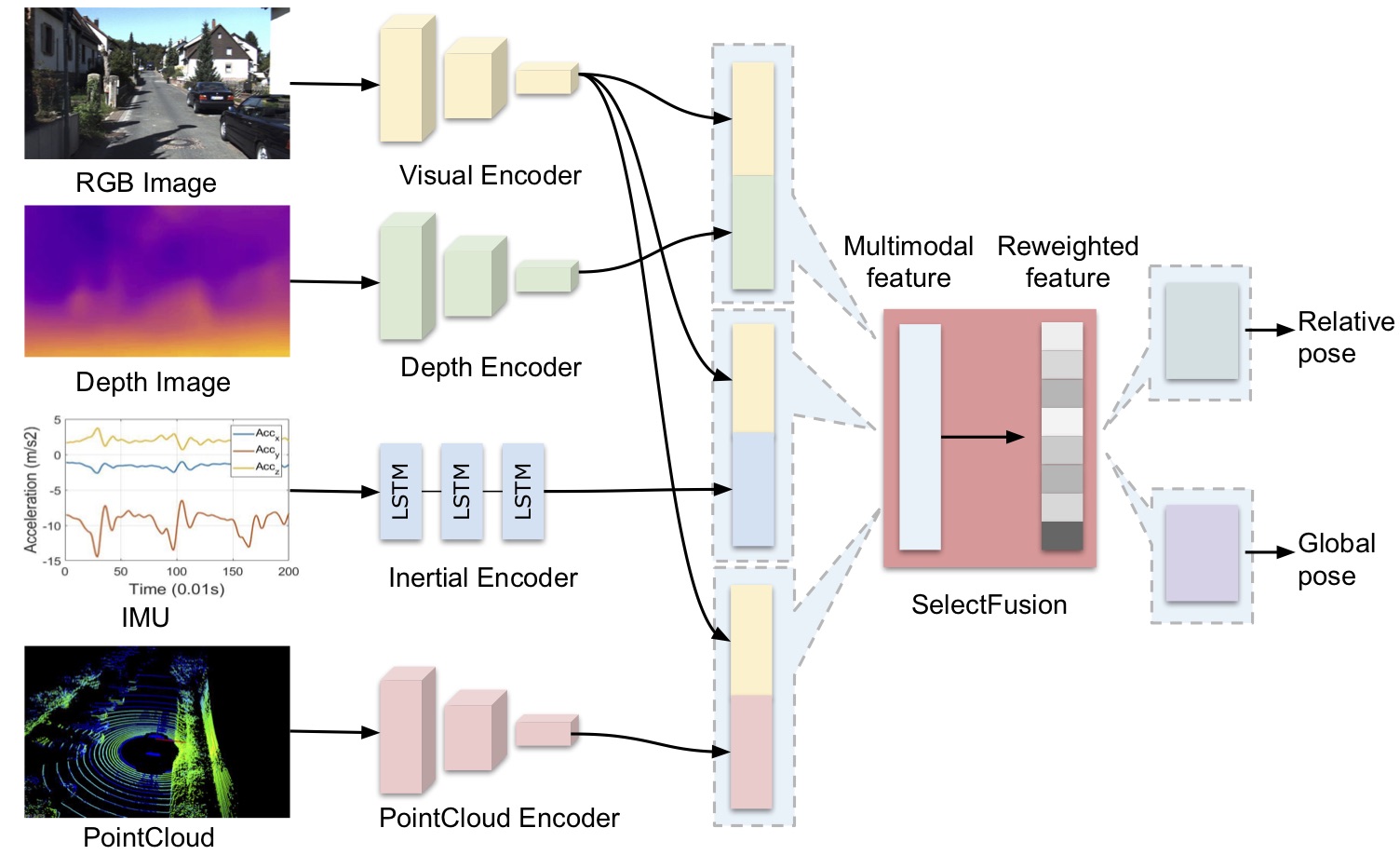
Learning selective sensor fusion for state estimation
Changhao
Chen, Stefano
Rosa, Chris Xiaoxuan
Lu, and
3 more authors
IEEE Transactions on Neural Networks and Learning Systems, 2022
we propose an end-to-end selective sensor fusion module that can be applied to modality pairs, such as monocular images and inertial measurements, depth images, and light detection and ranging (LIDAR) point clouds.
2021
-
Learning semantic segmentation of large-scale point clouds with random sampling
Qingyong
Hu, Bo
Yang, Linhai
Xie, and
5 more authors
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
2020
-
Randla-net: Efficient semantic segmentation of large-scale point clouds
Qingyong
Hu, Bo
Yang, Linhai
Xie, and
5 more authors
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020
We show that random sampling combined with attention can achieve SOA performances in semantic segmentation while processing large point clouds in near real-time.
2019
-
Selective sensor fusion for neural visual-inertial odometry
Changhao
Chen, Stefano
Rosa, Yishu
Miao, and
4 more authors
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
We show how data-learned sensor fusion strategies can improve accuracy and robustness in deep VIO when dealing with noisy/corrupted data, while adding interpretability.
2018
-
Semantic place understanding for human–robot coexistence—toward intelligent workplaces
Stefano
Rosa, Andrea
Patane, Chris Xiaoxuan
Lu, and
1 more author
IEEE Transactions on Human-Machine Systems, 2018
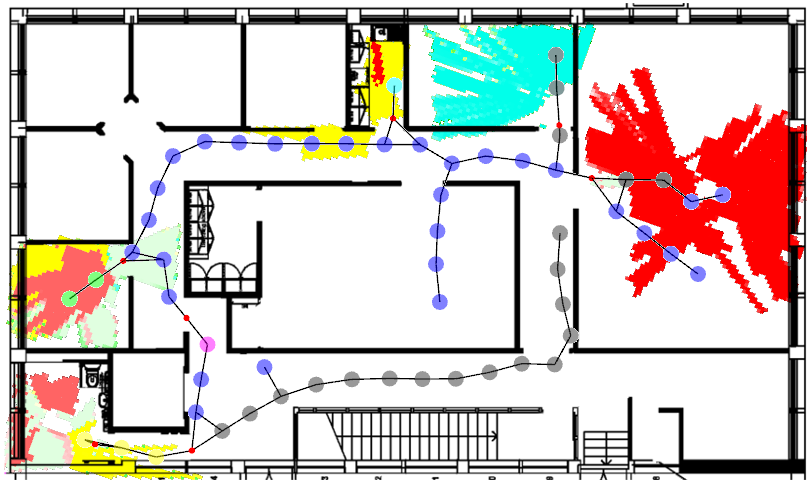
Robots and users can work synergistically by mutually learning over time, and benefitting from each other by exploiting each other’s strengths. We show how detecting user activities can help robots to learn semantic understanding of the environment, while at the same time learning to better localise the user.
-
Learning the intuitive physics of non-rigid object deformations
Zhihua
Wang, Stefano
Rosa, and Andrew
Markham
In Neural Information Processing Systems (NIPS) Workshops, 2018
-
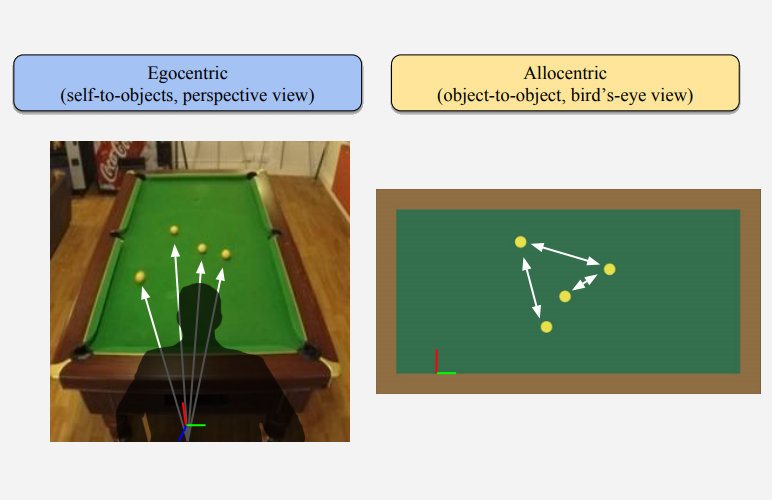
Neural allocentric intuitive physics prediction from real videos
Zhihua
Wang, Stefano
Rosa, Yishu
Miao, and
4 more authors
arXiv preprint arXiv:1809.03330, 2018
We learn how to predict future video of interacting objects by decoupling the problem into appearence and dynamics and leaning invertible transformations from real domain to simulation domain and from egocentric view to allocentric view and vice-versa.
-
Learning with training wheels: speeding up training with a simple controller for deep reinforcement learning
Linhai
Xie, Sen
Wang, Stefano
Rosa, and
2 more authors
In 2018 IEEE international conference on robotics and automation (ICRA), 2018
We propose a way to embed a switchable, simple controller into a deep reinforcement learning algorithm, to speed up training of mobile robot navigation in simulated environments.
-
3d-physnet: Learning the intuitive physics of non-rigid object deformations
Zhihua
Wang, Stefano
Rosa, Bo
Yang, and
3 more authors
In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, SWE, 2018
We show that conditioning a generative model that predicts soft object deformations on real physical properties can improve prediction accuracy as well as enabling generalisation abilities.
-
CommonSense: Collaborative learning of scene semantics by robots and humans
Stefano
Rosa, Andrea
Patanè, Xiaoxuan
Lu, and
1 more author
In Proceedings of the 1st International Workshop on Internet of People, Assistive Robots and Things, 2018
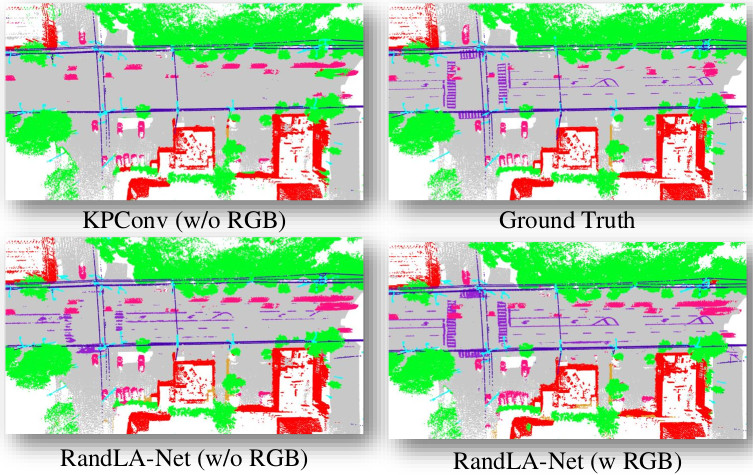 Learning semantic segmentation of large-scale point clouds with random samplingIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
Learning semantic segmentation of large-scale point clouds with random samplingIEEE Transactions on Pattern Analysis and Machine Intelligence, 2021

 Learning the intuitive physics of non-rigid object deformationsIn Neural Information Processing Systems (NIPS) Workshops, 2018
Learning the intuitive physics of non-rigid object deformationsIn Neural Information Processing Systems (NIPS) Workshops, 2018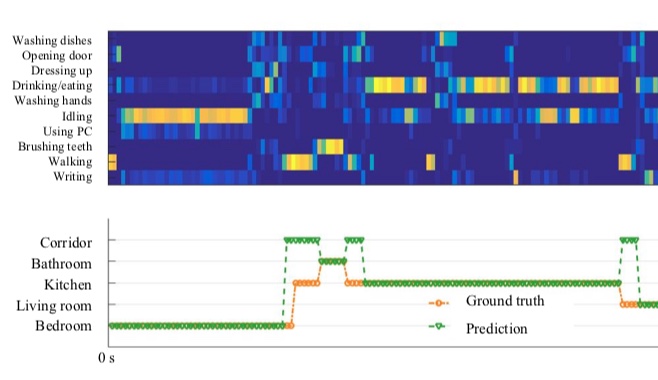 CommonSense: Collaborative learning of scene semantics by robots and humansIn Proceedings of the 1st International Workshop on Internet of People, Assistive Robots and Things, 2018
CommonSense: Collaborative learning of scene semantics by robots and humansIn Proceedings of the 1st International Workshop on Internet of People, Assistive Robots and Things, 2018